Certification track: AI Tooling
RAGFlow on Google Cloud Run
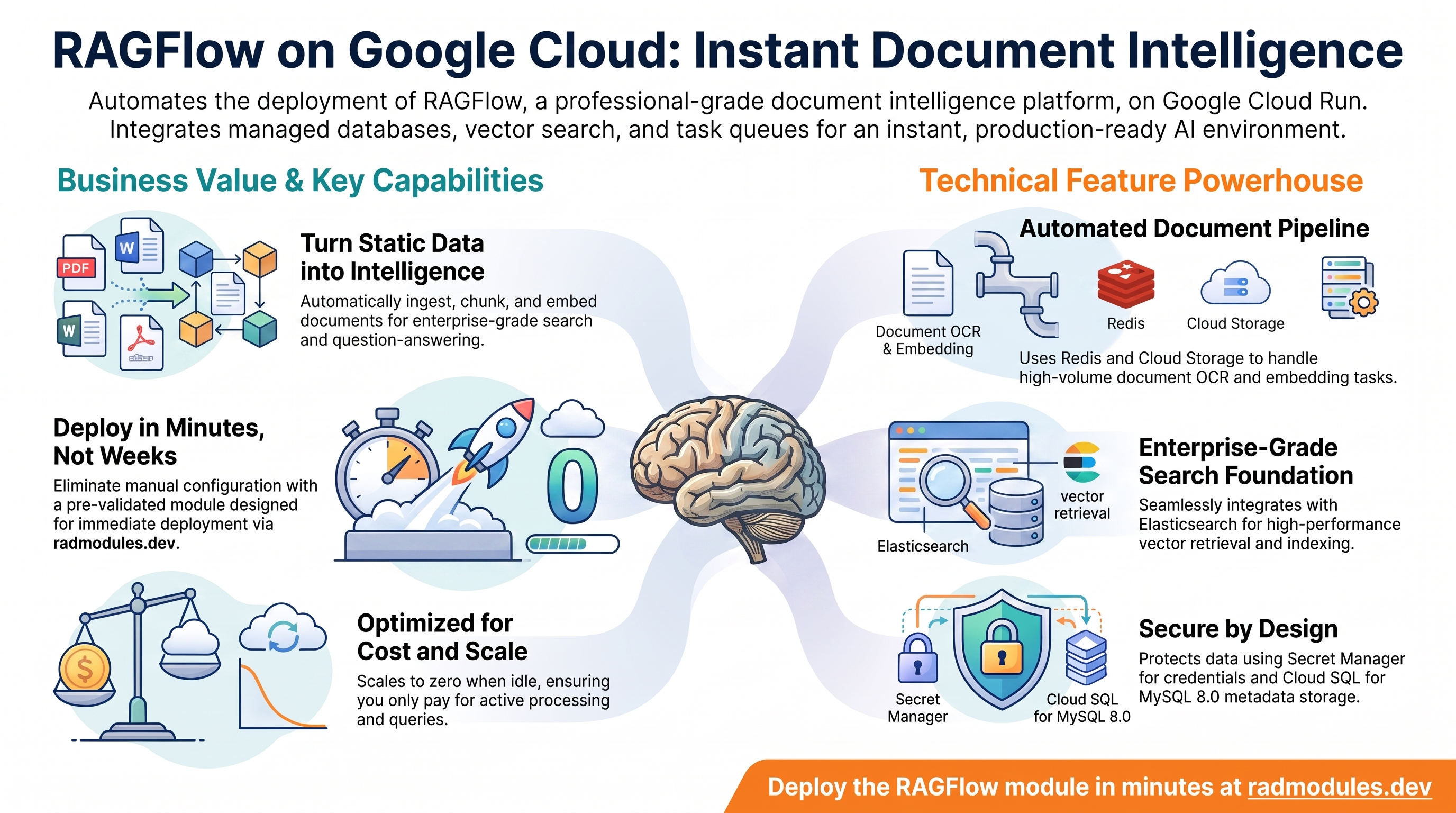
RAGFlow is an open-source document intelligence and Retrieval-Augmented Generation (RAG) platform. It ingests PDFs, Word documents, HTML pages, and other formats, chunks and embeds them, stores vectors in Elasticsearch, exposes a REST API for question-answering, and provides a web UI for knowledge base management and enterprise search. This module deploys RAGFlow on Cloud Run v2 on top of the App_CloudRun foundation, which provisions and manages the shared Google Cloud infrastructure.
This guide focuses on the cloud services RAGFlow uses and how to explore and operate them from the Google Cloud Console and the command line. For the mechanics common to every Cloud Run application — service identity, ingress and load balancing, scaling and concurrency, CI/CD, Cloud Armor, IAP, Binary Authorization, VPC Service Controls, backups, and the deployment lifecycle — refer to the App_CloudRun foundation guide rather than repeating them here.
Deployment prerequisite:
RAGFlow_CloudRunrequiresElasticsearch_GKEto be deployed first. Theelasticsearch_hostsvariable must be set whendeploy_application = true— the plan is rejected if it is empty.
1. Overview
RAGFlow runs as a containerised Python/Nginx service on Cloud Run v2. The deployment wires together a focused set of Google Cloud services:
| Capability | Google Cloud service | Notes |
|---|---|---|
| Compute | Cloud Run v2 | Custom-built RAGFlow service, 2 vCPU / 4 GiB by default, cold-start (min_instance_count = 0) by default |
| Database | Cloud SQL for MySQL 8.0 | Required — RAGFlow does not support PostgreSQL |
| Vector search | Elasticsearch (Elasticsearch_GKE) | External dependency — must be deployed first; elasticsearch_hosts is mandatory |
| Task queue | Redis (Memorystore) | Required for document processing workers |
| Object storage | Cloud Storage | A dedicated ragflow-documents bucket |
| Secrets | Secret Manager | Auto-generated database password |
| Ingress | Cloud Run URL / Cloud Load Balancing | Default run.app URL; optional Cloud Armor HTTPS load balancer + custom domain |
Sensible defaults worth knowing up front:
- MySQL 8.0 is mandatory. Selecting PostgreSQL or
NONEbreaks startup. elasticsearch_hostsis required. RAGFlow cannot index or search documents without a reachable Elasticsearch endpoint. This check is skipped only whendeploy_application = false.- Redis is required for document processing. With
enable_redis = true(default) and a non-emptyredis_host,REDIS_HOSTandREDIS_PORTare injected automatically. Without Redis, uploaded files remain unprocessed indefinitely. - Cold-start by default.
min_instance_count = 0andcpu_always_allocated = false(request-based billing) — the service scales to zero when idle and only bills CPU while serving a request. Trade-off: the background document task-executor stops when idle, so ingestion/parsing of newly uploaded documents does not run in the background; querying/chat still works on-request. Setcpu_always_allocated = trueandmin_instance_count >= 1to restore continuous background ingestion (and avoid the 2–3 minute cold-start while embedding models load). - Gen2 execution environment is required for NFS.
execution_environment = "gen2"is the default; switching togen1withenable_nfs = truefails at plan time. - A custom image is always built. Cloud Build extends
infiniflow/ragflowusing the Dockerfile inRAGFlow_Common/scripts/, withAPP_VERSIONset fromapplication_version. service_conf.yamlis generated at startup. The custom entrypoint writes/ragflow/conf/service_conf.yamlfrom injected environment variables before starting the RAGFlow processes. Asocatbridge adapts the Cloud SQL Auth Proxy Unix socket to the TCP port that RAGFlow's MySQL client expects.
2. Google Cloud Services & How to Explore Them
All commands assume PROJECT and REGION are set. Service and resource names are
reported in the deployment Outputs.
A. Cloud Run — the RAGFlow service
RAGFlow runs as a Cloud Run v2 service. By default it scales to zero when idle
(min_instance_count = 0, cpu_always_allocated = false); set both to keep an
instance warm and avoid cold-start delays during embedding model loading. Each
deployment creates an immutable revision; traffic can be split across revisions for
safe rollouts.
- Console: Cloud Run → select the service for revisions, traffic, logs, and metrics.
- CLI:
gcloud run services list --project "$PROJECT" --region "$REGION"
gcloud run services describe <service-name> --project "$PROJECT" --region "$REGION"
gcloud run revisions list --service <service-name> --project "$PROJECT" --region "$REGION"
See App_CloudRun for scaling, concurrency, execution environment, and traffic splitting.
B. Cloud SQL for MySQL 8.0
RAGFlow stores all application metadata (user accounts, knowledge bases, task state)
in a managed Cloud SQL for MySQL 8.0 instance. The service connects privately through
the Cloud SQL Auth Proxy sidecar via a Unix socket. A socat bridge inside the
container maps that socket to 127.0.0.1:3306 for RAGFlow's TCP MySQL client. On
first deploy an initialization Job creates the application database and user.
- Console: SQL → select the instance for connections, backups, flags, metrics.
- CLI:
gcloud sql instances list --project "$PROJECT"
gcloud sql instances describe <instance-name> --project "$PROJECT"
gcloud sql connect <instance-name> --user=<db-user> --project "$PROJECT"
The instance name, database, user, and password secret are in the Outputs. See App_CloudRun for the connection model, backups, and password rotation.
C. Elasticsearch — vector search
RAGFlow requires an external Elasticsearch instance for document indexing and vector
search. Deploy Elasticsearch_GKE separately and pass its elasticsearch_endpoint
output as elasticsearch_hosts. The environment variables ELASTICSEARCH_HOSTS and
ELASTICSEARCH_USERNAME are injected automatically. Inline Elasticsearch is not
supported on Cloud Run.
- Console: Kubernetes Engine → Workloads → Elasticsearch namespace.
- CLI:
# Confirm RAGFlow can reach Elasticsearch (from Cloud Shell or a VPC-connected host):
curl -s "$ELASTICSEARCH_HOSTS/_cluster/health" | grep status
D. Redis — task queue
Redis is the backbone of RAGFlow's document processing pipeline. Workers poll Redis
for tasks; without it, uploaded files are never parsed, chunked, or embedded. The
Memorystore Redis instance is accessed over the VPC via the PRIVATE_RANGES_ONLY
VPC egress setting (the default).
- Console: Memorystore → Redis (if using a managed instance).
- CLI:
redis-cli -h <redis-host> ping
redis-cli -h <redis-host> info keyspace
E. Cloud Storage
A dedicated Cloud Storage bucket (ragflow-documents) is provisioned for document
ingestion and storage. Additional buckets and GCS Fuse volume mounts can be added via
storage_buckets and gcs_volumes. The workload service account is granted access
automatically.
- Console: Cloud Storage → Buckets.
- CLI:
gcloud storage buckets list --project "$PROJECT"
gcloud storage ls gs://<documents-bucket>/ # bucket name is in the Outputs
See App_CloudRun for GCS Fuse and CMEK options.
F. Secret Manager
The database password is stored in Secret Manager and injected into the service at runtime; plaintext never appears in configuration.
- Console: Security → Secret Manager.
- CLI:
gcloud secrets list --project "$PROJECT"
gcloud secrets versions access latest --secret=<secret-name> --project "$PROJECT"
See App_CloudRun for injection and rotation details.
G. Networking & ingress
The service is reachable at its run.app URL by default. An external HTTPS load
balancer with Cloud Armor WAF, a custom domain, and Cloud CDN can be layered on.
VPC egress is set to PRIVATE_RANGES_ONLY by default so Redis and MySQL traffic
flows over the private VPC while public egress remains unrestricted.
- Console: Cloud Run (service URL); Network services → Load balancing.
- CLI:
gcloud run services describe <service-name> --region "$REGION" --format='value(status.url)'
gcloud compute addresses list --project "$PROJECT"
See App_CloudRun.
H. Cloud Logging & Monitoring
Container logs flow to Cloud Logging; Cloud Run and Cloud SQL metrics flow to Cloud Monitoring, with optional uptime checks and alert policies.
- Console: Logging → Logs Explorer; Monitoring → Dashboards / Alerting.
- CLI:
gcloud run services logs read <service-name> --project "$PROJECT" --region "$REGION" --limit 50
3. RAGFlow Application Behaviour
-
First-deploy database setup. An initialization Cloud Run Job (
mysql:8.0-debian) creates the RAGFlow database (rag_flow) and user (ragflow) before the service starts. It is idempotent and safe to re-run. -
service_conf.yamlgenerated at startup. The custom entrypoint generates/ragflow/conf/service_conf.yamlfrom injected environment variables — including MySQL host/user/database, Elasticsearch endpoint, Redis host/port, and optional credentials — before starting the RAGFlow processes. Asocatbridge adapts the Cloud SQL Auth Proxy Unix socket to127.0.0.1:3306for RAGFlow's MySQL client. -
Document processing pipeline. Uploaded documents are queued in Redis and processed asynchronously by RAGFlow's document workers: OCR, chunking, embedding, and indexing into Elasticsearch. Without a reachable Redis and Elasticsearch, files appear uploaded but are never processed.
-
Embedding model loading on startup. RAGFlow downloads and loads embedding models during first boot. The startup probe targets
/v1/system/versionwith a 120-second initial delay and 30 failure retries. Setmin_instance_count >= 1withcpu_always_allocated = trueto avoid cold starts and keep background document processing running continuously. -
Health endpoints. Startup and liveness probes use
/v1/system/version. The uptime check (if enabled) targets/v1/health. These return HTTP 200 only when the application is fully initialised.Inspect job executions:
gcloud run jobs list --project "$PROJECT" --region "$REGION"
gcloud run jobs executions list --job <job-name> --project "$PROJECT" --region "$REGION"
4. Configuration Variables
Variables are grouped exactly as they appear on the deployment platform. Only settings specific to or notable for RAGFlow are listed; every other input is inherited from App_CloudRun with its standard behaviour.
Group 1 — Project & Identity
| Variable | Default | Description |
|---|---|---|
project_id | (required) | Target Google Cloud project. |
region | us-central1 | Region for the service and regional resources. |
elasticsearch_hosts | (required) | Elasticsearch HTTP endpoint (e.g. http://10.0.0.5:9200). Set to the elasticsearch_endpoint output from Elasticsearch_GKE. |
Group 2 — Deployment Environment
| Variable | Default | Description |
|---|---|---|
tenant_deployment_id | demo | Short suffix that makes resource names unique per environment. |
support_users | [] | Emails granted project access and monitoring alerts. |
resource_labels | {} | Labels applied to all resources. |
Group 3 — Application Identity
| Variable | Default | Description |
|---|---|---|
application_name | ragflow | Base name for resources. Do not change after first deploy. |
display_name | RAGFlow | Friendly name shown in the Console. |
description | (set) | Service description. |
application_version | v0.13.0 | RAGFlow image version tag passed as APP_VERSION to Cloud Build; increment to roll out a new version. |
Group 4 — Runtime & Scaling
| Variable | Default | Description |
|---|---|---|
deploy_application | true | Set false to provision infrastructure only. |
cpu_limit | 2000m | CPU per instance; 4 vCPU or more recommended for production document processing. |
memory_limit | 4Gi | Memory per instance; 8–16 GiB recommended for production. |
cpu_always_allocated | false | Cost-first cold-start default. true restores continuous background document processing between requests. |
min_instance_count | 0 | Scales to zero when idle. Set ≥ 1 (with cpu_always_allocated = true) to keep the background task-executor and embedding models warm. |
max_instance_count | 1 | Maximum instances; increase with caution (requires NFS for shared storage). |
container_port | 80 | RAGFlow's Nginx frontend listens on port 80. |
execution_environment | gen2 | Must remain gen2 — required for NFS mounts. |
timeout_seconds | 600 | Increase for large document processing requests (max 3600). |
enable_cloudsql_volume | true | Cloud SQL Auth Proxy sidecar for socket connections. |
traffic_split | [] | Split traffic across revisions for staged rollouts. |
Group 5 — Access & Ingress Control
| Variable | Default | Description |
|---|---|---|
ingress_settings | all | Which networks may reach the service (all, internal, internal-and-cloud-load-balancing). |
vpc_egress_setting | PRIVATE_RANGES_ONLY | Route private RFC-1918 traffic (Redis, MySQL) through the VPC. |
enable_iap | false | Require Google sign-in via Identity-Aware Proxy. |
iap_authorized_users / iap_authorized_groups | [] | Who may access through IAP. |
Group 6 — Environment Variables & Secrets
| Variable | Default | Description |
|---|---|---|
environment_variables | {} | Extra non-secret settings. Do not override MYSQL_*, ELASTICSEARCH_*, or REDIS_* — these are injected automatically. |
secret_environment_variables | {} | Map of env var → Secret Manager secret name. |
secret_propagation_delay / secret_rotation_period | (set) | Replication wait / rotation cadence. |
Group 7 — Backup & Restore
| Variable | Default | Description |
|---|---|---|
backup_schedule | 0 2 * * * | Automated backup cron (UTC). |
backup_retention_days | 7 | Retention; raise for production/compliance. |
enable_backup_import / backup_source / backup_uri / backup_format | restore options | Restore from a backup on deploy. |
Group 8 — CI/CD & Binary Authorization
Standard App_CloudRun Cloud Build / Cloud Deploy integration — see
App_CloudRun. Key inputs: enable_cicd_trigger,
github_repository_url, github_token, enable_cloud_deploy,
enable_binary_authorization.
Group 9 — Custom SQL Scripts
enable_custom_sql_scripts, custom_sql_scripts_bucket, custom_sql_scripts_path,
custom_sql_scripts_use_root — run SQL from a GCS bucket after provisioning. See
App_CloudRun.
Group 10 — Cloud Armor, CDN & Custom Domain
| Variable | Default | Description |
|---|---|---|
enable_cloud_armor | false | Attach a Cloud Armor WAF policy via a Global HTTPS Load Balancer. |
admin_ip_ranges | [] | CIDRs allowed privileged access. |
application_domains | [] | Custom hostnames for the HTTPS load balancer. |
enable_cdn | false | Enable Cloud CDN on the LB backend. |
Group 11 — Storage & Filesystem
| Variable | Default | Description |
|---|---|---|
create_cloud_storage | true | Provision additional GCS buckets. The ragflow-documents bucket is always created. |
storage_buckets | [{ name_suffix="data" }] | Additional GCS bucket configurations. |
enable_nfs | true | Shared Filestore volume. Required for multi-instance deployments and when redis_host is empty (NFS server IP used as fallback Redis host). |
nfs_mount_path | /mnt/nfs | Mount path inside the container. |
gcs_volumes | [] | GCS Fuse volumes mounted into the RAGFlow container. |
manage_storage_kms_iam / enable_artifact_registry_cmek | false | CMEK options. |
Group 12 — Database Backend
| Variable | Default | Description |
|---|---|---|
database_type | MYSQL_8_0 | Fixed — do not change. |
db_name | rag_flow | Database name. Immutable after first deploy. |
db_user | ragflow | Application user. Immutable after first deploy. |
database_password_length | 32 | Generated password length (16–64). |
enable_auto_password_rotation / rotation_propagation_delay_sec | off | DB password rotation. |
db_host_env_var_name / db_name_env_var_name / db_user_env_var_name / db_port_env_var_name / service_url_env_var_name | "" | Additional env var names under which connection details are injected. |
Group 13 — Jobs & Scheduled Tasks
| Variable | Default | Description |
|---|---|---|
initialization_jobs | [] | Leave empty to use the built-in db-init Cloud Run Job. |
cron_jobs | [] | Recurring scheduled Cloud Run Jobs. |
Group 14 — Observability & Health
| Variable | Default | Description |
|---|---|---|
startup_probe | HTTP /v1/system/version, 120s delay, 30 retries | Allows ample time for embedding model loading on first boot. |
liveness_probe | HTTP /v1/system/version, 120s delay | Liveness probe once startup succeeds. |
uptime_check_config | disabled | Cloud Monitoring uptime check. |
alert_policies | [] | Metric alert policies. |
Group 15 — Elasticsearch & Redis
| Variable | Default | Description |
|---|---|---|
enable_redis | true | Use Redis for the document processing task queue. Redis is wired only when redis_host is non-empty. |
redis_host | "" | Redis endpoint. Must be set explicitly — no NFS-based auto-discovery on Cloud Run. |
redis_port | 6379 | Redis port. |
redis_auth | "" | Optional Redis auth password (sensitive). |
elasticsearch_username | "" | Elasticsearch username. Leave empty when xpack.security.enabled = false. |
Group 22 — VPC Service Controls & Audit Logging
| Variable | Default | Description |
|---|---|---|
enable_vpc_sc | false | Enforce a VPC-SC perimeter (requires organization_id). |
vpc_cidr_ranges / vpc_sc_dry_run | (set) | Access level CIDRs / dry-run mode. |
enable_audit_logging | false | Detailed Cloud Audit Logs. |
5. Outputs
Returned on a successful deployment — the quickest way to locate and explore the running resources.
| Output | Description |
|---|---|
service_name | Cloud Run service name. |
service_url | Default run.app URL of the service. |
service_location | Region the service runs in. |
stage_services | Stage-specific service details (Cloud Deploy). |
load_balancer_ip / load_balancer_url | External HTTPS load balancer IP / URL (when enabled). |
database_instance_name | Cloud SQL instance name. |
database_name / database_user | Application database name / user. |
database_password_secret | Secret Manager secret holding the DB password. |
database_host / database_port | DB endpoint / port. |
storage_buckets | Created Cloud Storage buckets. |
network_name / network_exists / regions | VPC network, presence, regions. |
container_image / container_registry | Deployed image and Artifact Registry repo. |
monitoring_enabled / monitoring_notification_channels / uptime_check_names | Monitoring status, channels, uptime checks. |
initialization_jobs | Names of the setup jobs. |
deployment_id / tenant_id / resource_prefix | Naming identifiers. |
project_id / project_number | Project identifiers. |
cicd_enabled / github_repository_url / github_repository_owner / github_repository_name / cicd_configuration | CI/CD status and details. |
artifact_registry_repository / cloudbuild_trigger_name / cloudbuild_trigger_id | Registry and build trigger. |
vpc_sc_enabled / vpc_sc_perimeter_name / vpc_sc_dry_run_mode | VPC-SC status. |
audit_logging_enabled / artifact_registry_cmek_enabled | Audit logging and CMEK status. |
6. Configuration Pitfalls & Sensible Defaults
Risk: Critical (data loss / outage / security) — High (service degraded) — Medium (cost or partial degradation) — Low (minor).
| Setting | Sensible value | Risk | Consequence if wrong |
|---|---|---|---|
elasticsearch_hosts | required — set from Elasticsearch_GKE | Critical | RAGFlow cannot index or search; all ingestion and retrieval operations fail. Plan is rejected when empty and deploy_application = true. |
enable_redis | true | Critical | Without Redis the document processing queue never runs; uploaded files remain unprocessed indefinitely. |
database_type | MYSQL_8_0 | Critical | RAGFlow requires MySQL; PostgreSQL/NONE breaks startup. |
enable_cloudsql_volume | true | Critical | RAGFlow connects via Unix socket bridged to TCP by socat; disabling the proxy sidecar causes a database connection failure on startup. |
db_name / db_user | set once | Critical | Immutable after first deploy; renaming recreates the database/user and destroys data. |
enable_backup_import | false unless restoring | Critical | Enabling without a valid backup_uri fails the import job. |
redis_host | explicit Memorystore IP | High | An unreachable or empty Redis host silently breaks all async document workers. There is no NFS-based auto-discovery fallback on Cloud Run. |
min_instance_count / cpu_always_allocated | 1 / true for continuous ingestion | High | Defaults are 0 / false (cold-start): background document processing stops while idle and cold starts take 2–3 minutes. Set both for always-on ingestion. |
memory_limit | 4Gi (≥ 8Gi for prod) | High | Embedding models plus the application server require significant RAM; too little causes OOM kills. |
vpc_egress_setting | PRIVATE_RANGES_ONLY | High | Memorystore Redis is on a private VPC IP; wrong egress routing breaks the task queue. |
execution_environment | gen2 | High | NFS mounts require gen2; switching to gen1 with enable_nfs = true fails at plan time. |
elasticsearch_username | "" or correct user | High | If Elasticsearch security is enabled, leaving this blank causes HTTP 401 and breaks all indexing. |
enable_nfs | true | High | Multi-instance deployments without shared storage see inconsistent document views across instances. |
ingress_settings / enable_iap | restrict for production | High | Public ingress with no IAP exposes RAGFlow to unauthenticated callers. |
max_instance_count | 1 (increase only with NFS) | Medium | Scaling beyond 1 without NFS causes split-brain document access across instances. |
timeout_seconds | 600 | Medium | Large document uploads can take several minutes; too short causes 504 timeouts before processing completes. |
backup_retention_days | 7 (raise for prod) | Medium | Too short for compliance retention. |
application_version | v0.13.0 | Medium | Incrementing triggers an image rebuild and revision rollout; verify MySQL schema compatibility for major version jumps. |
For the foundation behaviour referenced throughout — service identity, scaling and concurrency, ingress and load balancing, CI/CD, Cloud Armor, IAP, Binary Authorization, VPC-SC, backups, and image mirroring — see App_CloudRun. RAGFlow-specific application configuration shared with the GKE variant is described in RAGFlow_Common.