Certification track: Professional Cloud DevOps Engineer (PDE)
Kestra on Google Cloud Run
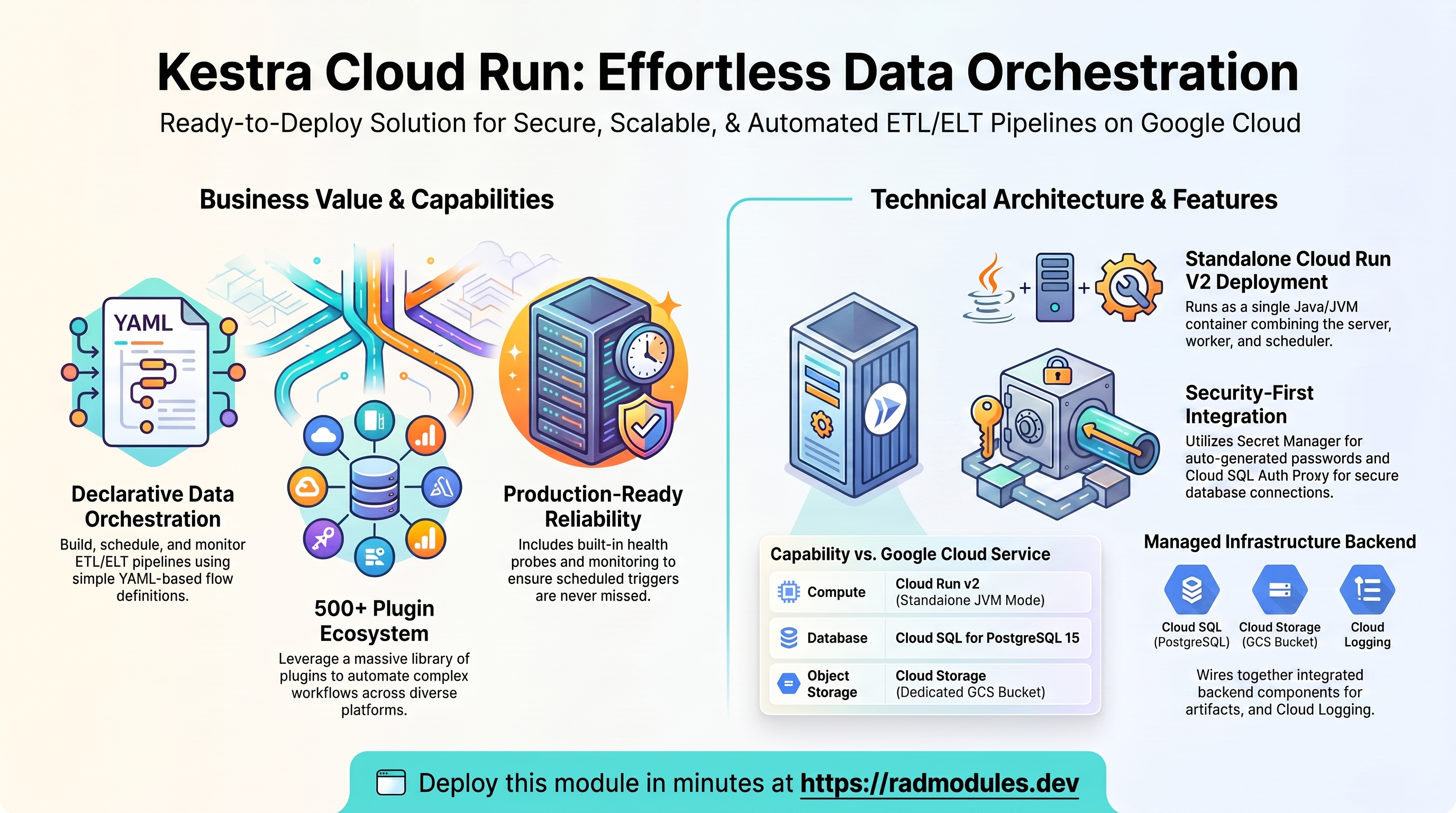
Kestra is an open-source data orchestration platform (Apache 2.0) for building, scheduling, and monitoring ETL/ELT pipelines, batch jobs, and workflow automation through declarative YAML-based flow definitions and a 500+ plugin ecosystem. This module deploys Kestra on Cloud Run v2 in standalone mode on top of the App_CloudRun foundation, which provisions and manages the shared Google Cloud infrastructure.
This guide focuses on the cloud services Kestra uses and how to explore and operate them from the Google Cloud Console and the command line. For the mechanics common to every Cloud Run application — service identity, ingress and load balancing, scaling and concurrency, CI/CD, Cloud Armor, IAP, Binary Authorization, VPC Service Controls, backups, and the deployment lifecycle — refer to the App_CloudRun foundation guide rather than repeating them here.
1. Overview
Kestra runs as a Java/JVM container on Cloud Run v2 in standalone mode (server, worker, and scheduler in a single container). The deployment wires together a focused set of Google Cloud services:
| Capability | Google Cloud service | Notes |
|---|---|---|
| Compute | Cloud Run v2 | Java/JVM service, 2 vCPU / 4 GiB by default, single-instance standalone mode |
| Database | Cloud SQL for PostgreSQL 15 | Required — stores queue, repository, and execution history |
| Object storage | Cloud Storage | Dedicated GCS bucket for flows, executions, and artifacts |
| Secrets | Secret Manager | Auto-generated Kestra admin password and database password |
| Ingress | Cloud Run URL / Cloud Load Balancing | Default run.app URL, optional external HTTPS load balancer + custom domain |
Sensible defaults worth knowing up front:
- PostgreSQL 15 is mandatory. Kestra uses PostgreSQL for both its internal queue and flow repository. MySQL is not supported.
- Standalone mode runs all components in one container. Keep
max_instance_count = 1to avoid conflicting queue-lock state across instances. - Java JVM cold start is slow. The default startup probe allows up to ~14 minutes. Keep
min_instance_count = 1in production so scheduled triggers are never missed. - Redis is not used. Kestra uses PostgreSQL for queuing in standalone mode.
- A Unix-socket bridge is built in. The Cloud SQL Auth Proxy creates a Unix socket, but
Java JDBC cannot connect via Unix sockets natively. The custom
entrypoint.shusessocatto bridge the socket to TCP127.0.0.1:5432transparently. - The admin password is auto-generated and stored in Secret Manager; it is never set in plain text.
- A GCS storage bucket is always provisioned for flows, executions, and artifacts; its
name is injected as
KESTRA_STORAGE_GCS_BUCKETautomatically.
2. Google Cloud Services & How to Explore Them
All commands assume PROJECT and REGION are set. Service and resource names are reported
in the deployment Outputs.
A. Cloud Run — the Kestra service
Kestra runs as a Cloud Run v2 service. Because Kestra's standalone mode combines server, worker, and scheduler in one process, it runs as a single long-running instance. Each deployment creates an immutable revision; traffic can be split across revisions for safe rollouts.
- Console: Cloud Run → select the service for revisions, traffic, logs, and metrics.
- CLI:
gcloud run services list --project "$PROJECT" --region "$REGION"
gcloud run services describe <service-name> --project "$PROJECT" --region "$REGION"
gcloud run revisions list --service <service-name> --project "$PROJECT" --region "$REGION"
See App_CloudRun for scaling, concurrency, execution environment, and traffic splitting.
B. Cloud SQL for PostgreSQL 15
Kestra stores all workflow state — flow definitions, execution history, triggers, namespaces,
and the internal task queue — in a managed Cloud SQL for PostgreSQL 15 instance. The service
connects through the Cloud SQL Auth Proxy over a Unix socket; the entrypoint.sh bridges
this socket to TCP so the Java JDBC driver can connect (no public IP is exposed). On first
deploy an initialization job creates the Kestra database, user, and grants required privileges.
- Console: SQL → select the instance for connections, backups, flags, and metrics.
- CLI:
gcloud sql instances list --project "$PROJECT"
gcloud sql instances describe <instance-name> --project "$PROJECT"
gcloud sql connect <instance-name> --user=<db-user> --project "$PROJECT"
The instance name, database, user, and password secret are in the Outputs. See App_CloudRun for the connection model, backups, and password rotation.
C. Cloud Storage
A dedicated Cloud Storage bucket is provisioned for Kestra's GCS artifact storage backend.
All flow executions, task inputs/outputs, and internal storage objects are written here. The
bucket name is injected into every instance as KESTRA_STORAGE_GCS_BUCKET. Additional buckets
or GCS Fuse volumes (requires gen2 execution environment) can be mounted for flow data
access.
- Console: Cloud Storage → Buckets.
- CLI:
gcloud storage buckets list --project "$PROJECT"
gcloud storage ls gs://<kestra-storage-bucket>/ # bucket name in Outputs
See App_CloudRun for GCS Fuse and CMEK options.
D. Secret Manager
The Kestra admin password and the database password are stored in Secret Manager and injected into the service at runtime. Plain text never appears in configuration.
- Console: Security → Secret Manager.
- CLI:
gcloud secrets list --project "$PROJECT"
gcloud secrets versions access latest --secret=<admin-password-secret> --project "$PROJECT"
The admin password secret is named <resource_prefix>-admin-password. The database password
secret name is in the Outputs. See App_CloudRun
for injection and rotation details.
E. Networking & ingress
The service is reachable at its run.app URL by default. An external HTTPS load balancer with
a custom domain, Cloud CDN, and Cloud Armor can be layered on; ingress settings and VPC egress
control connectivity.
- Console: Cloud Run (service URL); Network services → Load balancing.
- CLI:
gcloud run services describe <service-name> --region "$REGION" --format='value(status.url)'
gcloud compute addresses list --project "$PROJECT"
See App_CloudRun.
F. Cloud Logging & Monitoring
Container logs flow to Cloud Logging; Cloud Run and Cloud SQL metrics flow to Cloud Monitoring.
Health probes target Kestra's /health endpoint. Optional uptime checks and alert policies
are available (the uptime check is disabled by default — enable it for production monitoring).
- Console: Logging → Logs Explorer; Monitoring → Dashboards / Alerting.
- CLI:
gcloud run services logs read <service-name> --project "$PROJECT" --region "$REGION" --limit 50
3. Kestra Application Behaviour
- First-deploy database setup. An initialization job (
db-init) usespostgres:15-alpineto connect through the Cloud SQL Auth Proxy and idempotently creates the Kestra database and user, grants privileges, and resets the public schema so Flyway can apply all migrations cleanly on a fresh Cloud SQL instance. The job signals the proxy to shut down cleanly when done. - Flyway migrations on start. Kestra runs Flyway-based schema migrations on every startup.
The
FLYWAY_DATASOURCES_POSTGRES_BASELINE_ON_MIGRATE=truesetting prevents failures on Cloud SQL, which pre-populates the public schema with extension objects. Upgrading theapplication_versionapplies schema changes automatically. - Unix-socket to TCP bridge. Cloud Run's Cloud SQL Auth Proxy creates a Unix socket at
${DB_HOST}/.s.PGSQL.5432. Java JDBC cannot connect via Unix socket natively. The customentrypoint.shdetects this socket, creates a symlink at/tmp/cloudsql.sock(to avoid colon-separator issues), and starts asocatbridge forwarding TCP127.0.0.1:5432to the socket. TheDATASOURCES_POSTGRES_URL,DATASOURCES_POSTGRES_USERNAME, andDATASOURCES_POSTGRES_PASSWORDJDBC vars are then assembled from the platform-injectedDB_*environment variables before Kestra is launched. - Health endpoint. Startup and liveness probes target
GET /healthon port 8080. The default startup probe allows up to ~14 minutes for JVM startup. The infrastructure-level startup probe is TCP (no path), giving Cloud Run's routing layer a simple liveness signal before the application probe takes over. - Admin login. The initial admin username is
admin. The password is retrieved from Secret Manager (see §2.D). - Scheduled triggers. Kestra's internal scheduler processes flow-defined triggers (cron,
interval, webhook).
min_instance_count = 1ensures one warm instance is always available. Scale-to-zero (0) causes missed trigger windows during cold starts.
4. Configuration Variables
Variables are grouped exactly as they appear on the deployment platform. Only settings specific to or notable for Kestra are listed; every other input is inherited from App_CloudRun with its standard behaviour.
Group 1 — Project & Identity
| Variable | Default | Description |
|---|---|---|
project_id | (required) | Target Google Cloud project. |
region | us-central1 | Region for the service and regional resources. |
Group 2 — Deployment Environment
| Variable | Default | Description |
|---|---|---|
tenant_deployment_id | demo | Short suffix that makes resource names unique per environment. |
support_users | [] | Emails granted project access and monitoring alerts. |
resource_labels | {} | Labels applied to all resources. |
Group 3 — Application Identity
| Variable | Default | Description |
|---|---|---|
application_name | kestra | Base name for resources. Do not change after first deploy. |
application_version | latest | Kestra image version tag; increment to roll out a new version (e.g. 0.17.0). |
display_name | Kestra Data Orchestration | Friendly name shown in the Console and platform UI. |
description | Kestra Data Orchestration - ETL/ELT pipeline and workflow orchestration on Cloud Run | Cloud Run service description. |
deploy_application | true | Set false to provision infrastructure only. |
Group 4 — Runtime & Scaling
| Variable | Default | Description |
|---|---|---|
cpu_limit | 2000m | CPU per instance; 2 vCPU minimum recommended for Kestra JVM. |
memory_limit | 4Gi | Memory per instance; 4 GiB recommended (minimum 2 GiB). |
container_port | 8080 | Kestra/Micronaut server port. Must match MICRONAUT_SERVER_PORT. |
min_instance_count | 1 | Minimum instances. Keep ≥ 1 so scheduled triggers are never missed. |
max_instance_count | 1 | Maximum instances. Keep at 1 for standalone mode to avoid queue conflicts. |
timeout_seconds | 300 | Maximum request duration in seconds. |
execution_environment | gen2 | gen2 is required for GCS Fuse volume mounts. |
enable_cloudsql_volume | true | Cloud SQL Auth Proxy sidecar — required for the Unix-socket JDBC bridge. |
enable_image_mirroring | true | Mirror the Kestra image into Artifact Registry before deploy. |
cpu_always_allocated | true | Keep CPU allocated at all times (recommended for the Kestra scheduler). |
ingress_settings | all | Which networks may reach the service: all, internal, or internal-and-cloud-load-balancing. |
vpc_egress_setting | PRIVATE_RANGES_ONLY | How outbound traffic is routed through the VPC connector. |
traffic_split | [] | Traffic allocation across revisions for staged rollouts. |
max_revisions_to_retain | 7 | How many old revisions to keep. |
Group 5 — Environment Variables & Secrets
| Variable | Default | Description |
|---|---|---|
environment_variables | {} | Extra non-secret settings. Core Kestra vars are injected automatically; do not override them here. |
secret_environment_variables | {} | Map of env var → Secret Manager secret name. |
secret_propagation_delay | 30 | Seconds to wait after secret creation (0–300). |
secret_rotation_period | 2592000s | Secret Manager rotation notification period. |
enable_auto_password_rotation | false | Automated zero-downtime DB password rotation. |
rotation_propagation_delay_sec | 90 | Seconds to wait after rotation before restarting the service. |
Group 7 — Backup & Restore
| Variable | Default | Description |
|---|---|---|
backup_schedule | 0 2 * * * | Automated backup cron (UTC). |
backup_retention_days | 7 | Retention; raise for production/compliance. |
enable_backup_import / backup_source / backup_uri / backup_format | restore options | Restore from a backup on deploy. |
Group 8 — CI/CD & Binary Authorization
Standard App_CloudRun Cloud Build / Cloud Deploy integration — see
App_CloudRun. Key inputs: enable_cicd_trigger,
github_repository_url, github_token, enable_cloud_deploy,
enable_binary_authorization.
Group 9 — NFS & Custom SQL
| Variable | Default | Description |
|---|---|---|
enable_nfs | false | Provision a Cloud Filestore (NFS) share and mount it into the service. Requires gen2. |
nfs_mount_path | /mnt/nfs | Mount path inside the container. |
enable_custom_sql_scripts / custom_sql_scripts_bucket / custom_sql_scripts_path / custom_sql_scripts_use_root | off | Run SQL from a GCS bucket after provisioning. See App_CloudRun. |
Group 10 — Domain, CDN, Cloud Armor & Image Retention
| Variable | Default | Description |
|---|---|---|
application_domains | [] | Custom hostnames for the external HTTPS load balancer. |
enable_cdn | false | Enable Cloud CDN on the HTTPS LB backend. Requires enable_cloud_armor = true. |
enable_cloud_armor / admin_ip_ranges | off | Attach a WAF policy / restrict privileged access. |
max_images_to_retain / delete_untagged_images / image_retention_days | (set) | Artifact Registry cleanup policy. |
Group 11 — Storage
| Variable | Default | Description |
|---|---|---|
create_cloud_storage | true | Provision additional buckets in storage_buckets. The Kestra storage bucket is always created. |
storage_buckets | [] | Additional GCS buckets beyond the built-in storage bucket. |
gcs_volumes | [] | GCS buckets to mount via GCS Fuse (requires gen2). |
manage_storage_kms_iam / enable_artifact_registry_cmek | false | CMEK options. |
Group 12 — Database Backend
| Variable | Default | Description |
|---|---|---|
db_name | kestra | PostgreSQL database name. Immutable after first deploy. |
db_user | kestra | Application user. Immutable after first deploy. |
database_type | POSTGRES_15 | Cloud SQL engine. Kestra requires PostgreSQL. |
database_password_length | 32 | Generated password length (16–64). |
enable_cloudsql_volume | true | Required for the Unix-socket JDBC bridge. |
Group 13 — Jobs & Scheduled Tasks
| Variable | Default | Description |
|---|---|---|
initialization_jobs | [] | Leave empty to use the built-in db-init job. Provide a non-empty list to replace it entirely. |
cron_jobs | [] | Recurring Cloud Run Jobs triggered by Cloud Scheduler. |
additional_services | [] | Supplementary Cloud Run services deployed alongside the main Kestra service. |
Group 14 — Observability & Health
| Variable | Default | Description |
|---|---|---|
startup_probe | HTTP /health, 30s delay, period 20s, 40 failures | Application startup probe — allows up to ~14 minutes for JVM startup. |
liveness_probe | HTTP /health, 180s delay, period 30s, 5 failures | Application liveness probe. |
startup_probe_config | TCP, no path | Infrastructure-level startup probe (does not follow HTTP redirects). |
uptime_check_config | disabled, path /health | Cloud Monitoring uptime check. Enable for production monitoring. |
alert_policies | [] | Metric alert policies. |
Group 20 — Identity-Aware Proxy (IAP)
| Variable | Default | Description |
|---|---|---|
enable_iap | false | Require Google sign-in via Identity-Aware Proxy. |
iap_authorized_users / iap_authorized_groups | [] | Who may access through IAP. |
Group 22 — VPC Service Controls & Audit Logging
| Variable | Default | Description |
|---|---|---|
enable_vpc_sc | false | Enforce a VPC-SC perimeter (requires organization_id). |
vpc_cidr_ranges / vpc_sc_dry_run | (set) | Access level CIDRs / dry-run mode. |
enable_audit_logging | false | Detailed Cloud Audit Logs. |
5. Outputs
Returned on a successful deployment — the quickest way to locate and explore the running resources.
| Output | Description |
|---|---|
service_name | Cloud Run service name. |
service_url | Default run.app URL of the service. |
service_location | Region the service runs in. |
stage_services | Stage-specific service URLs (Cloud Deploy). |
load_balancer_ip / load_balancer_url | External HTTPS load balancer IP / URL (when enabled). |
database_instance_name | Cloud SQL instance name. |
database_name / database_user | Application database name / user. |
database_password_secret | Secret Manager secret holding the DB password. |
database_host / database_port | DB endpoint / port. |
storage_buckets | Created Cloud Storage buckets (includes the Kestra storage bucket). |
network_name / network_exists / regions | VPC network, presence, regions. |
container_image / container_registry | Deployed image and Artifact Registry repo. |
monitoring_enabled / monitoring_notification_channels / uptime_check_names | Monitoring status, channels, uptime checks. |
initialization_jobs | Names of the setup jobs. |
deployment_id / tenant_id / resource_prefix | Naming identifiers. |
project_id / project_number | Project identifiers. |
cicd_enabled / cicd_configuration | CI/CD status and details. |
github_repository_url / github_repository_owner / github_repository_name | GitHub repo details. |
artifact_registry_repository / cloudbuild_trigger_name / cloudbuild_trigger_id | Registry and build trigger. |
vpc_sc_enabled / vpc_sc_perimeter_name / vpc_sc_dry_run_mode | VPC-SC status. |
audit_logging_enabled / artifact_registry_cmek_enabled | Audit logging and CMEK status. |
6. Configuration Pitfalls & Sensible Defaults
Risk: Critical (data loss / outage / security) — High (service degraded) — Medium (cost or partial degradation) — Low (minor).
| Setting | Sensible value | Risk | Consequence if wrong |
|---|---|---|---|
db_name | kestra — set once | Critical | Immutable after first deploy; changing it connects Kestra to an empty database, losing all flows, execution history, triggers, and namespaces. |
application_name | kestra — set once | Critical | Immutable after first deploy; changing it renames all GCP resources, causing full recreation with data loss. |
KESTRA_BASICAUTH_ENABLED (injected true) | leave as injected | Critical | Overriding to false exposes the full Kestra UI and REST API without authentication. Only disable behind a trusted auth proxy (IAP, Cloud Armor). |
enable_backup_import | false unless restoring | Critical | Enabling without a valid backup_uri fails the import job. |
max_instance_count | 1 | High | Multiple instances cause PostgreSQL queue-lock conflicts and task double-assignment in Community Edition. |
min_instance_count | 1 | High | Setting to 0 causes scheduled triggers to be missed during cold-start periods. |
memory_limit | 4Gi | High | Values below 2 GiB cause JVM OutOfMemoryErrors under concurrent execution load. |
enable_cloudsql_volume | true | High | Required for the Unix-socket JDBC bridge; without it the entrypoint.sh socket bridge has no socket to bridge. |
KESTRA_QUEUE_TYPE / KESTRA_REPOSITORY_TYPE (injected postgres) | leave as injected | High | Only PostgreSQL is provisioned; overriding to an unsupported backend causes startup failure. |
execution_environment | gen2 | High | NFS and GCS Fuse mounts require gen2; changing to gen1 causes mount failures. |
startup_probe failure threshold | 40 (default) | High | Reducing below ~10 causes premature restarts on slow JVM startup before Kestra has finished loading. |
ENDPOINTS_ALL_PORT (injected 8080) | leave as injected | High | Overriding this port breaks Cloud Run health checks, causing continuous container restarts. |
min_instance_count | 1 | Medium | Setting to 0 adds cold-start latency and risks missed scheduled work. |
ingress_settings | all (or LB-only for prod) | Medium | Setting to internal blocks all external webhook triggers and API calls from outside the VPC. |
enable_iap / enable_cloud_armor | enable for admin-facing | Medium | The Kestra UI and API are otherwise publicly reachable. |
backup_retention_days | 7 (raise for prod) | Medium | Too short for compliance retention requirements. |
organization_id | set when using VPC-SC | Medium | If empty, VPC Service Controls are silently skipped. |
Destroying resources — known Cloud Run subnet delay
When destroying this deployment you may encounter:
Error: Error waiting for Subnetwork to be deleted: The following serverless IPv4 address(es)
on subnet ... are still in use.
GCP holds serverless IPv4 addresses asynchronously after the Cloud Run service is deleted. Wait 20–30 minutes after the initial destroy attempt and re-run the destroy command; it will succeed once GCP has released the reserved addresses.
For the foundation behaviour referenced throughout — service identity, scaling and concurrency, ingress and load balancing, CI/CD, Cloud Armor, IAP, Binary Authorization, VPC-SC, backups, and image mirroring — see App_CloudRun. Kestra-specific application configuration shared with the GKE variant is described in Kestra_Common.